A widely held belief underpinning asset allocation decisions for long-term investors is that higher risk assets, on average, outperform lower risk assets. This (expected, not guaranteed) outperformance is known as a risk premium1.
In the context of DB pensions, risk premiums are consequential assumptions influencing the choice of investment strategy, and level of contributions. As a result, there are often discussions/disagreements/bunfights around what the ‘correct’ risk premiums should be for different asset classes.
This blog examines the assumption that there exists a ‘correct’ risk premium for different asset classes and explores the implications if this belief is shaky. For ease we’ll focus on the most famous example – the equity risk premium (“ERP”).
First, some modelling
Let’s pretend that equity returns all come from an unseen, unchanging, ‘true’ distribution (we don’t actually know this but bear with us). How much return data do we need before we can infer, with some reasonable degree of confidence, what the true expected return on equity is?
We can test this by running many simulations, with all returns generated randomly from our ‘true’ distribution2. This is an example of a well-known technique called Monte Carlo modelling3. One of the benefits of this approach is that we can explore many ‘simulated histories,’ which is helpful, given we only have one ‘actual history’ to guide us.
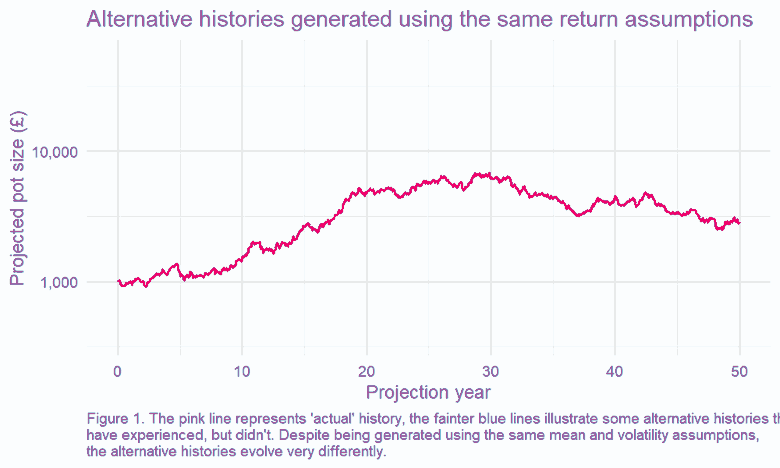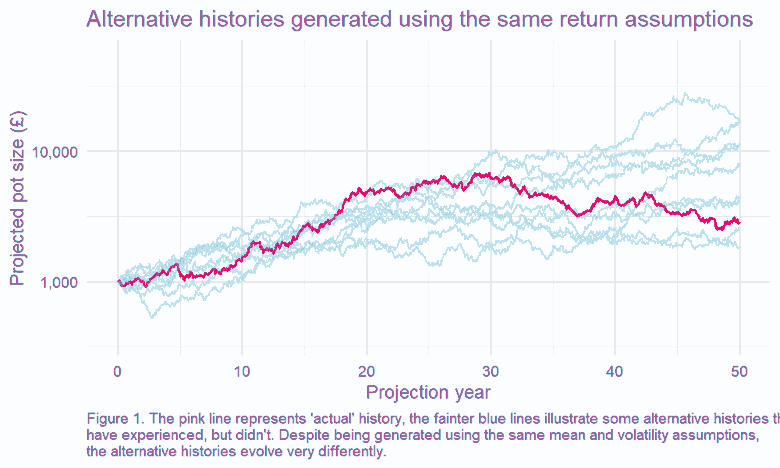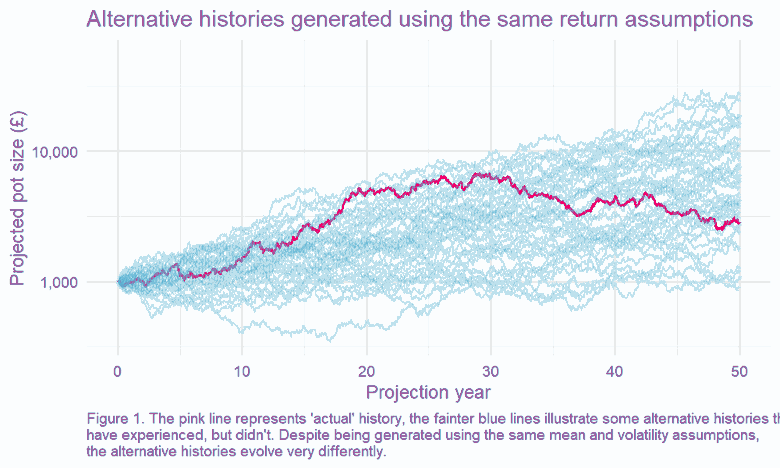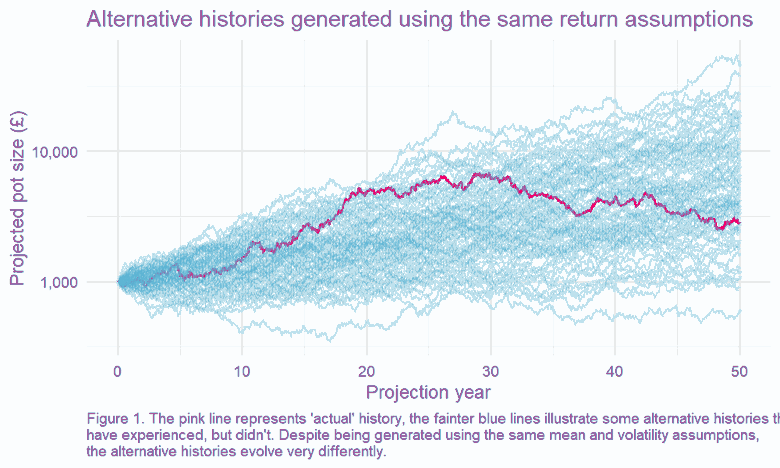
This, in turn, means we can look at the spread of outcomes driven by the randomness of the underlying return process. This is charted below – how quickly do our observed (annualised) returns converge on the underlying ‘true’ average return?4

The results are stark: even for equities, the asset class for which we’ve got the most historical data5, we can only pin down our error range to c. +/- 1% if we want to have the same confidence as a coin flip. The variability of the historically observed returns year on year clouds our estimate of the true expected return.
This shows that there’s a fair degree of uncertainty in pinning down an ERP. However, this ‘parameter uncertainty’ is often ignored in long-term financial modelling, where a two-step process is typically followed:
-
Calibrate an economic scenario generator (choosing values for parameters like the ERP in the process); and
-
Use scenarios from the economic scenario generator in order to explore the long run risk/return profile of alternative investment strategies.
Does ignoring parameter uncertainty really matter? Well, what if we happen (by chance) to have been overly optimistic when calibrating the ERP? Below we compare the range of investment outcomes under our example where we the expected return is known and fixed, versus a situation where we allow this expected return to vary randomly at a level below this point estimate6.
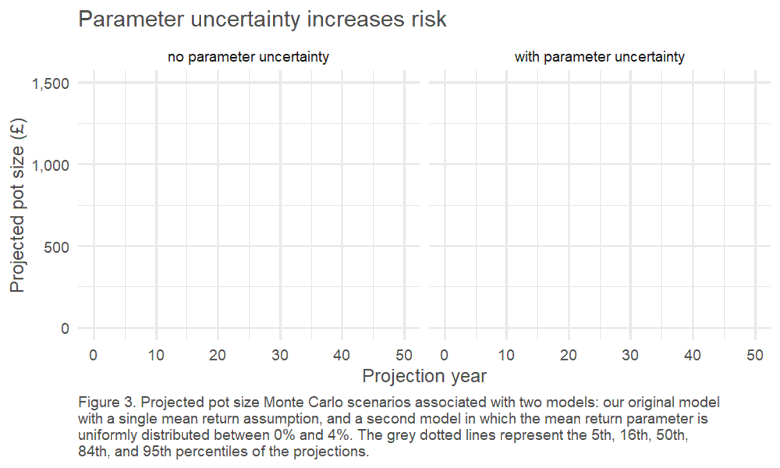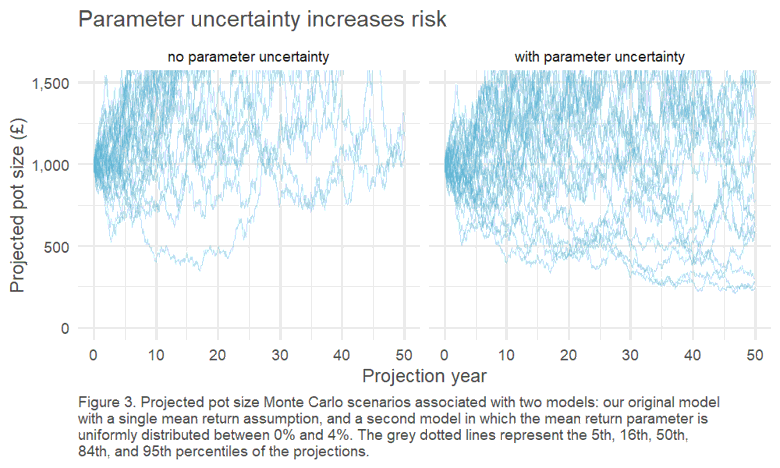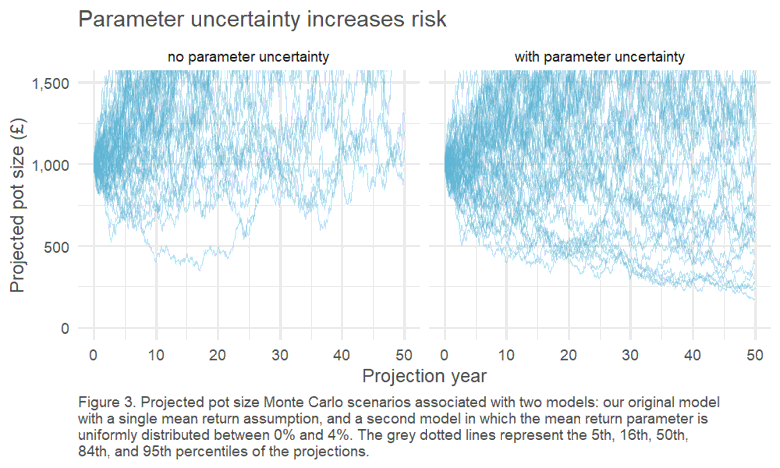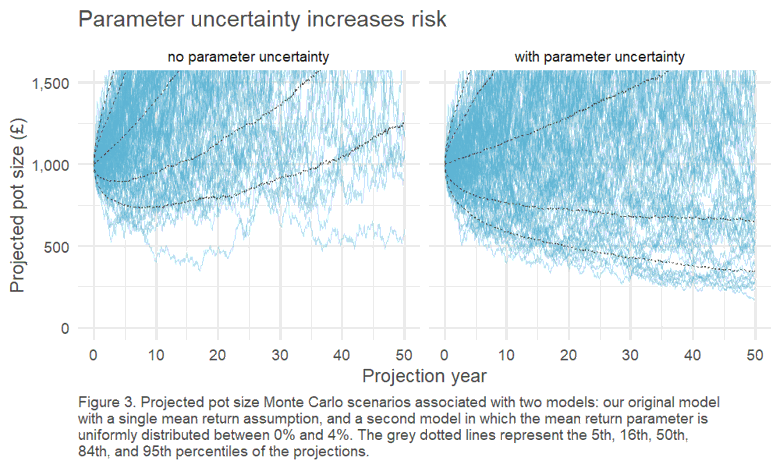
When we ignore parameter uncertainty, the likelihood that equity will lose money over a multi-decade horizon is remote; however, when we allow for parameter uncertainty, this is clearly a much more tangible possibility.
We’re not suggesting that modelling is useless. A model is simply a tool that enables us to explore the consequences of our assumptions about the future in a controlled way. It is designed to help the user profit; it is not designed to be a prophet. Modelling risk is as much about communicating the risks which aren’t captured within the framework as it is about understanding those which are.











